MinerU 功能与使用说明文档
MinerU 功能与使用说明文档
1. 项目概述
MinerU是一款开源的PDF文档智能解析工具,旨在将复杂的PDF文档转换为机器可读的格式(如Markdown、JSON),为AI时代的大模型训练、RAG应用、知识图谱构建等提供高质量的数据支持。该项目诞生于InternLM书生·浦语大模型的预训练过程中,专注于解决科技文献中的符号转化问题,特别是在学术论文、技术报告等专业文档中的数学公式、表格、复杂排版等内容的精确识别。
MinerU的核心定位是为企业和研究机构提供一站式文档数字化解决方案,通过深度学习技术实现文档内容的结构化提取,保留原文档的语义信息和视觉结构,为大模型应用提供高质量的训练数据和推理输入。该项目适用于学术研究、企业文档管理、知识库建设、法律文书分析等多个场景。
作为开源项目,MinerU在GitHub上获得了超过53.8k星标和4.5k分叉,体现了其在技术社区中的广泛认可和影响力。项目采用AGPL-3.0许可证,确保了开源生态的健康发展。相比国内外知名商用产品,MinerU虽然在功能成熟度上仍有提升空间,但凭借其开源免费、高度可定制、持续更新的特点,为用户提供了一个强大的文档解析选择。
2. 功能特性
2.1 主要功能模块
智能布局分析
- 自动检测和识别文档的布局结构,包括单栏、多栏、复杂排版等不同格式
- 精确识别标题层级、段落划分、列表结构等语义单元
- 智能判断内容的阅读顺序,确保输出文本符合人类阅读习惯
- 支持跨栏、跨页、跨图表的内容合理排序和拼接
多语言OCR识别
- 支持109种语言的检测与识别,覆盖全球主要语言体系
- 针对中文、英文、日文、韩文等亚洲语言进行了特别优化
- 自动识别扫描版PDF和乱码PDF,智能启用OCR功能
- 支持手写体文本识别,提升对多样化文档类型的适应能力
数学公式处理
- 自动识别并转换文档中的数学公式为LaTeX格式
- 支持行内公式和独立公式的精确识别
- 针对中英文混合公式进行了专门优化
- 提供公式识别开关,可根据需求灵活控制功能启用
表格结构解析
- 自动识别文档中的表格结构,包括有框表格、无框表格、半结构化表格
- 支持表格的HTML格式输出,保持原始表格的布局信息
- 智能识别表格标题、表格脚注等相关内容
- 支持跨页表格的自动合并,提升表格完整性
图像内容提取
- 自动提取文档中的图像内容
- 支持图像描述文字的识别和提取
- 保留图像的位置信息和视觉特征
- 支持图像与描述文字的智能关联
智能内容过滤
- 自动识别并删除页眉、页脚、脚注、页码等干扰元素
- 保留文档的核心内容,确保语义连贯性
- 智能区分正文内容和辅助信息
2.2 技术特点
多后端架构设计
MinerU采用模块化的后端设计,支持多种解析后端以适应不同的应用场景:
- Pipeline后端:基于传统机器学习 pipeline 的后端,具有良好的兼容性,支持纯CPU环境运行,适用于资源受限的场景
- VLM后端:基于视觉语言大模型的后端,提供更高的解析精度(90+),支持更复杂的内容理解,但需要GPU硬件支持
- Hybrid后端:混合后端,结合了Pipeline和VLM的优势,在高精度的基础上增加了额外的扩展性
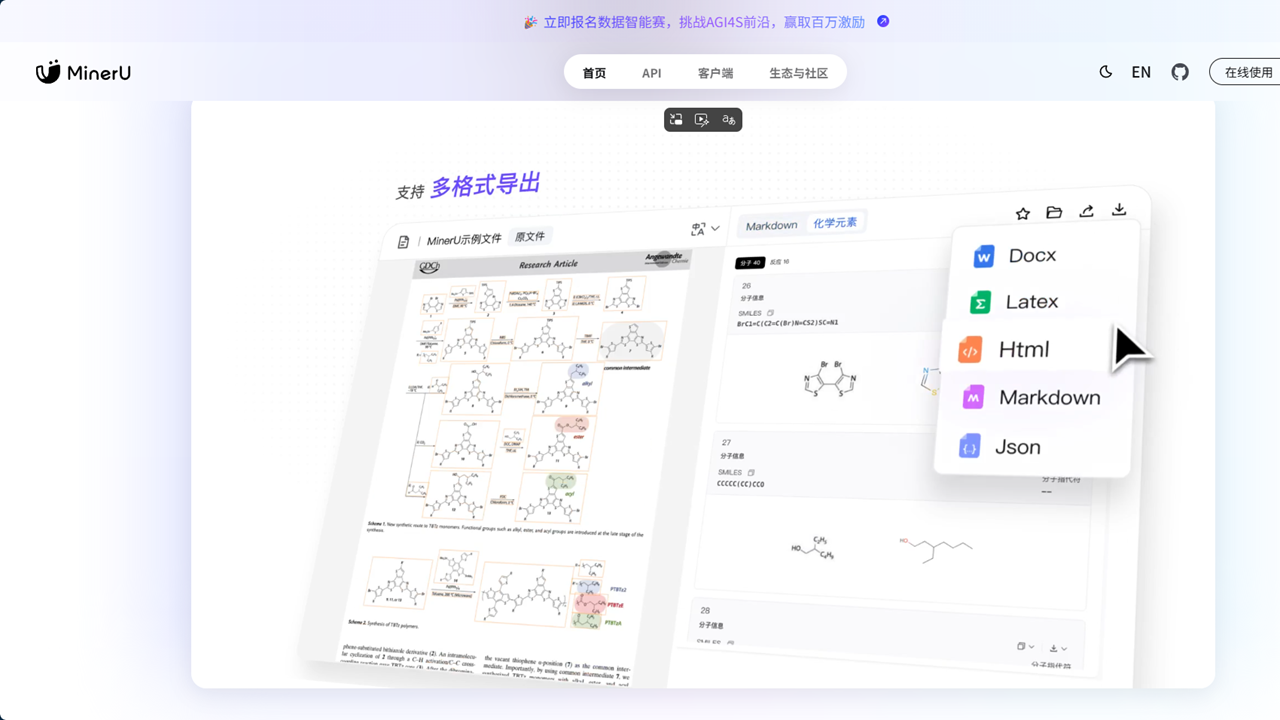
多种输出格式
- Markdown格式:适用于大多数文本处理场景,支持多模态和NLP应用的Markdown输出
- JSON格式:按阅读顺序排序的结构化数据,便于程序化处理和二次开发
- 中间格式:包含丰富信息的中间文件,用于调试和质量检查
- 可视化文件:提供布局可视化、span可视化等调试文件,便于用户理解解析过程
硬件加速支持
- GPU加速:支持CUDA加速,适用于NVIDIA显卡
- NPU加速:支持华为昇腾等国产NPU加速卡
- MPS加速:支持Apple Silicon芯片的加速
- 纯CPU模式:在无专用硬件的情况下仍可正常运行
跨平台兼容性
- Windows:支持Windows 10及以上版本
- Linux:支持主流Linux发行版(2019年及以后)
- macOS:支持macOS 14.0及以上版本
2.3 与同类工具的差异化优势
高精度解析
- 在OmniDocBench等权威基准测试中,MinerU2.5模型(仅1.2B参数)在布局分析、文本识别、公式识别、表格识别、阅读顺序等五个关键领域全面超越GPT-4o、Gemini 2.5 Pro等顶级模型
- 相比专业的文档解析工具,MinerU在复杂表格、旋转表格、长公式等挑战性场景中表现更优
开源性
- 完全开源,用户可以自由查看、修改和定制源代码
- 社区驱动,持续接收用户反馈并快速迭代优化
- 无供应商锁定风险,支持私有化部署和数据安全
灵活的部署方式
- 支持本地部署、云端部署、容器化部署等多种部署模式
- 提供命令行工具、API接口、Web界面等多种交互方式
- 支持轻量级客户端到完整功能套件的不同安装选项
国产化适配
- 官方支持包括昇腾、平头哥、沐曦、海光、燧原、摩尔线程、天数智芯、寒武纪等在内的多种国产算力平台
- 在政府、军工、金融等对信息安全有特殊要求的场景中具有重要价值
丰富的扩展性
- 支持自定义公式分隔符、标题分类、本地模型目录等配置扩展
- 提供完善的API接口,便于与现有系统集成
- 支持基于配置文件的功能扩展,无需修改源代码
3. 安装指南
3.1 环境要求
硬件要求
Pipeline后端:
- CPU:多核处理器(建议4核以上)
- 内存:最低16GB,推荐32GB或以上
- 磁盘空间:最低20GB,推荐使用SSD
- GPU:可选,支持Turing架构及以后的NVIDIA显卡(6GB+显存)或Apple Silicon
VLM后端:
- CPU:多核处理器(建议8核以上)
- 内存:最低8GB
- 磁盘空间:最低2GB
- GPU:必须,支持Turing架构及以后的NVIDIA显卡(10GB+显存)
软件要求
操作系统:
- Windows:Windows 10及以上版本
- Linux:2019年及以后发行版(如Ubuntu 20.04+, CentOS 8+)
- macOS:14.0及以上版本
Python版本:3.10-3.13(Windows平台仅支持3.10-3.12)
依赖软件:
- Git:用于源代码安装
- CUDA:GPU加速需要(支持CUDA 11.8/12.4/12.6/12.8)
- Docker:容器化部署可选
3.2 依赖配置
基础依赖
MinerU的基础依赖包括Python运行环境、基础科学计算库等。通过pip安装时会自动处理大部分依赖关系。
GPU加速依赖
如果需要GPU加速,需要安装支持CUDA的PyTorch版本。Windows用户需要根据CUDA版本选择合适的PyTorch安装命令,具体可参考PyTorch官方文档。
VLM加速引擎
VLM后端支持多种加速引擎,包括transformers、vllm、lmdeploy等。不同引擎有不同的硬件要求和性能特点,用户可根据实际需求选择。
3.3 安装步骤
方式一:使用pip或uv安装(推荐)
# 升级pip
pip install --upgrade pip
# 安装uv(更快的包管理工具)
pip install uv
# 安装MinerU完整版(包含所有功能)
uv pip install -U "mineru[all]"
方式二:从源码安装
# 克隆仓库
git clone https://github.com/opendatalab/MinerU.git
cd MinerU
# 安装开发版本
uv pip install -e .[all]
方式三:Docker部署
# 下载Dockerfile
wget https://gcore.jsdelivr.net/gh/opendatalab/MinerU@master/docker/global/Dockerfile
# 构建镜像
docker build -t mineru:latest -f Dockerfile .
# 启动容器
docker run --gpus all \
--shm-size 32g \
-p 30000:30000 -p 7860:7860 -p 8000:8000 \
--ipc=host \
-it mineru:latest \
/bin/bash
不同操作系统的适配方案
Windows系统:
- 推荐使用Anaconda或Miniconda管理Python环境
- GPU加速需要提前安装CUDA驱动和CUDA工具包
- 可能需要安装Visual C++ Redistributable
Linux系统:
- 推荐使用系统包管理器安装基础依赖
- Ubuntu/Debian系统可能需要安装额外字体:
sudo apt update sudo apt install fonts-noto-core sudo apt install fonts-noto-cjk fc-cache -fv - GPU加速需要安装NVIDIA驱动和CUDA工具包
macOS系统:
- 推荐使用Homebrew管理Python环境
- Apple Silicon芯片可使用MPS加速
- 可能需要安装Xcode命令行工具
扩展模块安装
如果需要特定的功能模块,可以选择性安装:
- 仅核心功能(不含vllm加速):
uv pip install mineru[core] - 包含vllm加速:
uv pip install mineru[all] - 轻量级客户端(连接到vllm-server):
uv pip install mineru
4. 使用教程
4.1 基础操作流程
首次使用配置
MinerU首次使用时会自动从HuggingFace下载所需模型文件。如果无法访问HuggingFace,可以通过环境变量切换到ModelScope镜像:
export MINERU_MODEL_SOURCE=modelscope
简单命令行使用
最基本的PDF解析命令:
# 使用默认backend(pipeline)解析PDF
mineru -p input.pdf -o output_directory
# 使用VLM后端解析PDF(需要GPU)
mineru -p input.pdf -o output_directory -b vlm-transformers
批量处理
MinerU支持批量处理多个PDF文件:
# 处理整个目录中的PDF文件
mineru -p input_directory -o output_directory
# 处理指定PDF文件
mineru -p file1.pdf file2.pdf -o output_directory
4.2 核心功能调用方法
解析方法选择
# 自动模式(默认):智能判断是否需要OCR
mineru -p input.pdf -o output -m auto
# 文本模式:直接提取PDF中的文本(适合文本型PDF)
mineru -p input.pdf -o output -m txt
# OCR模式:强制使用OCR识别(适合扫描版PDF)
mineru -p input.pdf -o output -m ocr
后端选择
# Pipeline后端(兼容性好,支持纯CPU)
mineru -p input.pdf -o output -b pipeline
# VLM后端(精度高,需要GPU)
mineru -p input.pdf -o output -b vlm-transformers
# VLM with vLLM加速(速度最快)
mineru -p input.pdf -o output -b vlm-vllm-engine
# VLM HTTP客户端(连接到远程服务)
mineru -p input.pdf -o output -b vlm-http-client -u http://server:30000
语言设置
# 指定文档语言(仅pipeline后端有效)
mineru -p input.pdf -o output -l ch # 中文
mineru -p input.pdf -o output -l en # 英文
mineru -p input.pdf -o output -l korean # 韩文
mineru -p input.pdf -o output -l japan # 日文
功能开关控制
# 禁用公式识别
mineru -p input.pdf -o output --formula false
# 禁用表格识别
mineru -p input.pdf -o output --table false
# 指定设备
mineru -p input.pdf -o output -d cuda:0 # 使用第一个GPU
mineru -p input.pdf -o output -d cpu # 使用CPU
4.3 常见任务的实现路径
学术论文解析
对于包含大量数学公式的学术论文:
# 使用VLM后端以获得最佳效果
mineru -p academic_paper.pdf -o output -b vlm-transformers
# 如果GPU显存不足,使用Pipeline后端
mineru -p academic_paper.pdf -o output -b pipeline
扫描文档处理
对于扫描版PDF或图像文件:
# 强制使用OCR模式
mineru -p scanned_doc.pdf -o output -m ocr -l en
# 中文扫描文档
mineru -p scanned_chinese.pdf -o output -m ocr -l ch
表格密集型文档
对于包含大量表格的财务报告或技术文档:
# 确保表格识别功能启用
mineru -p financial_report.pdf -o output --table true
# 使用VLM后端处理复杂表格
mineru -p complex_tables.pdf -o output -b vlm-transformers
多语言文档处理
对于包含多种语言的文档:
# 自动语言识别
mineru -p multilingual_doc.pdf -o output -m auto
# 指定主要语言
mineru -p multilingual_doc.pdf -o output -l ch
特定页面解析
如果只需要解析文档的特定页面:
# 解析第5-10页(页面索引从0开始)
mineru -p document.pdf -o output -s 5 -e 10
# 解析前3页
mineru -p document.pdf -o output -s 0 -e 3
4.4 高级使用方式
Python API调用
from mineru import MinerU
# 创建解析器实例
mineru = MinerU()
# 解析PDF文件
result = mineru.parse("input.pdf", output_dir="output")
# 访问解析结果
markdown_content = result["markdown"]
json_content = result["json"]
FastAPI服务部署
# 启动API服务
mineru-api --host 127.0.0.1 --port 8000
# 访问API文档
# 浏览器打开 http://127.0.0.1:8000/docs
Gradio WebUI使用
# 启动Gradio Web界面
mineru-gradio --server-port 7860 --enable-example true
# 访问Web界面
# 浏览器打开 http://127.0.0.1:7860
vLLM服务器部署
# 启动vLLM服务器
mineru-openai-server --port 30000
# 在另一个终端使用HTTP客户端连接
mineru -p input.pdf -o output -b vlm-http-client -u http://127.0.0.1:30000
5. 参数说明
5.1 核心命令行参数
输入输出参数
-p, --path PATH:输入文件路径或目录(必需参数)-o, --output PATH:输出目录(必需参数)-s, --start INTEGER:起始页码(从0开始)-e, --end INTEGER:结束页码(从0开始)
解析控制参数
-m, --method [auto|txt|ocr]:解析方法- auto:自动判断(默认)
- txt:直接提取文本
- ocr:强制OCR识别
-b, --backend [pipeline|vlm-transformers|vlm-vllm-engine|vlm-http-client]:解析后端- pipeline:传统pipeline后端(默认)
- vlm-transformers:VLM后端(transformers引擎)
- vlm-vllm-engine:VLM后端(vLLM加速引擎)
- vlm-http-client:VLM HTTP客户端
-l, --lang [ch|ch_server|ch_lite|en|korean|japan|chinese_cht|...]:文档语言设置-f, --formula BOOLEAN:是否启用公式识别(默认启用)-t, --table BOOLEAN:是否启用表格识别(默认启用)
硬件配置参数
-d, --device TEXT:推理设备(如cpu/cuda/cuda:0/npu/mps)--vram INTEGER:最大GPU显存使用量(GB),仅pipeline后端有效
模型源参数
--source [huggingface|modelscope|local]:模型源- huggingface:HuggingFace模型库(默认)
- modelscope:ModelScope模型库
- local:本地模型
5.2 环境变量配置
通用环境变量
MINERU_MODEL_SOURCE:模型源设置export MINERU_MODEL_SOURCE=modelscope # 切换到ModelScope export MINERU_MODEL_SOURCE=local # 使用本地模型MINERU_DEVICE_MODE:推理设备设置export MINERU_DEVICE_MODE=cuda:0 # 使用第一个GPU export MINERU_DEVICE_MODE=cpu # 使用CPUMINERU_VIRTUAL_VRAM_SIZE:GPU显存限制(GB)export MINERU_VIRTUAL_VRAM_SIZE=8 # 限制显存使用为8GB
功能控制环境变量
MINERU_FORMULA_ENABLE:公式识别开关export MINERU_FORMULA_ENABLE=false # 禁用公式识别MINERU_TABLE_ENABLE:表格识别开关export MINERU_TABLE_ENABLE=false # 禁用表格识别MINERU_TABLE_MERGE_ENABLE:表格合并开关export MINERU_TABLE_MERGE_ENABLE=false # 禁用表格合并MINERU_FORMULA_CH_SUPPORT:中文公式支持(实验性功能)export MINERU_FORMULA_CH_SUPPORT=1 # 启用中文公式优化
性能调优环境变量
MINERU_PDF_RENDER_TIMEOUT:PDF渲染超时时间(秒)export MINERU_PDF_RENDER_TIMEOUT=600 # 设置超时为10分钟MINERU_INTRA_OP_NUM_THREADS:ONNX模型内操作线程数export MINERU_INTRA_OP_NUM_THREADS=4 # 设置内操作线程数为4MINERU_INTER_OP_NUM_THREADS:ONNX模型间操作线程数export MINERU_INTER_OP_NUM_THREADS=2 # 设置间操作线程数为2MINERU_API_MAX_CONCURRENT_REQUESTS:API最大并发请求数export MINERU_API_MAX_CONCURRENT_REQUESTS=10 # 设置最大并发为10
配置文件环境变量
MINERU_TOOLS_CONFIG_JSON:配置文件路径export MINERU_TOOLS_CONFIG_JSON=/custom/path/mineru.json
5.3 高级参数配置
GPU设备选择
# 指定特定GPU
CUDA_VISIBLE_DEVICES=1 mineru -p input.pdf -o output
# 指定多个GPU
CUDA_VISIBLE_DEVICES=0,1 mineru -p input.pdf -o output
# 多卡并行vLLM服务器
CUDA_VISIBLE_DEVICES=0,1 mineru-vllm-server --port 30000 --data-parallel-size 2
vLLM参数优化
# 多卡并行处理
mineru -p input.pdf -o output -b vlm-vllm-engine --data-parallel-size 2
# 其他vLLM参数
mineru -p input.pdf -o output -b vlm-vllm-engine --tensor-parallel-size 2
Gradio WebUI配置
# 启动Gradio服务
mineru-gradio --server-port 7860 \
--enable-example true \
--enable-api true \
--max-convert-pages 100 \
--latex-delimiters-type all
Docker Compose配置
# 启动vLLM服务器
docker compose -f compose.yaml --profile vllm-server up -d
# 启动API服务
docker compose -f compose.yaml --profile api up -d
# 启动Gradio界面
docker compose -f compose.yaml --profile gradio up -d
6. 高级应用
6.1 配置文件自定义
MinerU支持通过配置文件进行功能扩展和个性化设置。配置文件通常位于用户目录下,名为mineru.json。
生成配置文件
# 使用模型下载命令生成配置文件
mineru-models-download
# 或者复制模板文件手动创建
cp mineru.template.json ~/.mineru/mineru.json
LaTeX公式分隔符配置
"latex-delimiter-config": {
"display": {
"left": "$$",
"right": "$$"
},
"inline": {
"left": "$",
"right": "$"
}
}
LLM辅助标题分类配置
"llm-aided-config": {
"title_aided": {
"api_key": "your_api_key",
"base_url": "https://dashscope.aliyuncs.com/compatible-mode/v1",
"model": "qwen3-next-80b-a3b-instruct",
"enable_thinking": false,
"enable": true
}
}
本地模型目录配置
"models-dir": {
"pipeline": "/path/to/pipeline/models",
"vlm": "/path/to/vlm/models"
}
对象存储配置
"bucket_info": {
"bucket-name-1": ["access_key", "secret_key", "endpoint"],
"bucket-name-2": ["access_key", "secret_key", "endpoint"]
}
6.2 性能优化技巧
GPU内存优化
# 限制GPU显存使用
export MINERU_VIRTUAL_VRAM_SIZE=6
# 使用更小的批次处理
mineru -p input.pdf -o output --vram 4
CPU线程优化
# 设置ONNX模型线程数
export MINERU_INTRA_OP_NUM_THREADS=4
export MINERU_INTER_OP_NUM_THREADS=2
批量处理优化
# 使用脚本批量处理
for file in *.pdf; do
mineru -p "$file" -o output/ --table true --formula true
done
模型加速优化
# 使用vLLM加速(适合大规模处理)
mineru -p input.pdf -o output -b vlm-vllm-engine
# 使用LMdeploy加速(Windows平台友好)
mineru -p input.pdf -o output -b vlm-lmdeploy-engine
# 使用MLX加速(Apple Silicon)
mineru -p input.pdf -o output -b vlm-mlx-engine
分布式处理
# 启动vLLM服务器
mineru-openai-server --port 30000 --data-parallel-size 2
# 在多个客户端连接
mineru -p input1.pdf -o output1 -b vlm-http-client -u http://server:30000
mineru -p input2.pdf -o output2 -b vlm-http-client -u http://server:30000
6.3 自定义扩展方法
自定义预处理脚本
用户可以编写自定义的预处理脚本来对输入文档进行特殊处理,然后调用MinerU进行解析。
自定义后处理流程
解析完成后,用户可以根据需要对Markdown或JSON输出进行进一步的处理和格式化。
集成到现有系统
# 示例:集成到Flask应用
from flask import Flask, request
from mineru import MinerU
import os
app = Flask(__name__)
mineru = MinerU()
@app.route('/parse', methods=['POST'])
def parse_document():
file = request.files['file']
output_dir = 'temp_output'
os.makedirs(output_dir, exist_ok=True)
result = mineru.parse(file, output_dir=output_dir)
return {"markdown": result["markdown"]}
if __name__ == '__main__':
app.run(host='0.0.0.0', port=5000)
二次开发
MinerU提供了丰富的中间输出文件(如middle.json、model.json等),开发者可以基于这些文件进行二次开发,构建定制化的文档处理流程。
6.4 国产算力平台适配
MinerU已官方适配多种国产算力平台,包括:
昇腾(Ascend)
- 支持Atlas A2/A3训练系列和推理系列
- 支持使用vLLM或LMdeploy进行加速
- 提供专门的Dockerfile和部署指南
平头哥(T-Head)
- 支持倚天710等处理器
- 提供完整的部署文档和示例
沐曦(METAX)
- 支持C1024等GPU产品
- 兼容主流CUDA生态
海光(Hygon)
- 支持DCU系列加速器
- 提供ROCm支持
燧原(Enflame)
- 支持云燧T20/T21等加速卡
- 完整的软件栈支持
摩尔线程(MooreThreads)
- 支持MUSA S3000等GPU
- 提供CUDA兼容层
天数智芯(IluvatarCorex)
- 支持智铠100等加速卡
- 完整的软件支持
寒武纪(Cambricon)
- 支持MLU系列芯片
- 提供BANG语言支持
7. 常见问题
7.1 安装相关问题
Q:安装过程中出现依赖冲突
A:建议使用uv包管理器进行安装,它比pip更快且能更好地处理依赖冲突。如果仍然出现问题,可以尝试使用Docker部署方式。
Q:Windows系统下安装失败
A:确保Python版本在3.10-3.12之间,Windows暂不支持Python 3.13。同时确保已安装Visual C++ Redistributable。
Q:Linux系统下缺少字体导致解析结果丢失
A:安装必要的字体包:
sudo apt update
sudo apt install fonts-noto-core
sudo apt install fonts-noto-cjk
fc-cache -fv
Q:模型下载失败
A:可以切换模型源到ModelScope:
export MINERU_MODEL_SOURCE=modelscope
或者使用Docker部署,镜像中已包含必要的模型文件。
7.2 运行时问题
Q:出现ImportError: libGL.so.1: cannot open shared object file错误
A:在Ubuntu 22.04 WSL2环境中,需要安装libgl库:
sudo apt-get install libgl1-mesa-glx
Q:GPU内存不足
A:可以通过以下方式解决:
- 使用Pipeline后端替代VLM后端
- 限制GPU显存使用:
--vram 4 - 设置环境变量:
export MINERU_VIRTUAL_VRAM_SIZE=4
Q:解析速度过慢
A:可以尝试以下优化:
- 使用VLM后端配合vLLM加速
- 关闭不需要的功能:
--formula false或--table false - 使用更快的硬件配置
Q:OCR识别准确率不高
A:可以尝试:
- 明确指定文档语言:
-l ch或-l en - 使用VLM后端获得更高的精度
- 对于特定语言的扫描文档,选择合适的语言模型
7.3 结果质量问题
Q:表格识别不准确
A:复杂表格的识别是一个技术难点,可以尝试:
- 使用VLM后端获得更好的效果
- 手动调整表格合并参数
- 对识别结果进行人工校正
Q:公式无法在Markdown中正确渲染
A:部分复杂的公式可能无法在Markdown中完全还原,这是由于Markdown本身的表达限制。可以考虑:
- 使用HTML格式输出
- 查看原始LaTeX代码
- 使用专门的数学公式渲染器
Q:阅读顺序混乱
A:在极端复杂的排版下,模型可能会出现阅读顺序判断错误。可以尝试:
- 使用VLM后端获得更准确的阅读顺序
- 调整文档格式或扫描质量
- 对结果进行人工校正
Q:跨页内容处理不当
A:确保已启用表格合并功能:
export MINERU_TABLE_MERGE_ENABLE=true
7.4 高级使用问题
Q:如何设置并发推理?
A:可以通过以下方式设置并发:
- 设置环境变量:
export MINERU_API_MAX_CONCURRENT_REQUESTS=10 - 使用多卡并行:
--data-parallel-size 2 - 启动多个服务实例
Q:如何使用自定义模型?
A:需要:
- 下载模型到本地目录
- 在配置文件中设置模型路径
- 设置环境变量:
export MINERU_MODEL_SOURCE=local
Q:如何调试解析问题?
A:可以使用可视化调试文件:
- 查看
*_layout.pdf了解布局分析结果 - 查看
*_span.pdf了解文本分割情况 - 查看
middle.json了解详细的解析过程
Q:Docker部署中如何增加并发?
A:可以:
- 修改Docker Compose配置文件
- 调整vLLM服务器的并发参数
- 使用多容器部署
7.5 性能调优问题
Q:如何优化解析速度?
A:可以从以下几个方面优化:
- 硬件升级:使用更快的GPU/NPU
- 软件优化:使用vLLM加速引擎
- 功能优化:关闭不需要的功能模块
- 批量处理:合理安排批量处理任务
Q:内存占用过高如何解决?
A:可以尝试:
- 限制GPU显存使用
- 减少并发数量
- 使用Pipeline后端替代VLM后端
- 分批处理大文件
Q:如何处理超大的PDF文件?
A:对于超大文件(如超过1000页):
- 分页处理:使用
-s和-e参数分批次处理 - 增加系统内存
- 使用更强大的硬件配置
- 考虑分布式处理
7.6 社区支持和反馈
如果遇到文档中没有解决的问题,用户可以通过以下渠道获得帮助:
- 查看FAQ文档:访问MinerU官方文档网站的FAQ部分
- 使用DeepWiki AI助手:在GitHub Discussions中提到的AI助手可以帮助解决大部分常见问题
- 提交Issue:在GitHub上提交详细的Issue,包括复现步骤和相关信息
- 参与Discussions:在GitHub Discussions板块与其他用户和开发者交流
- 加入社区:通过Discord或微信社区获得实时帮助
结语
MinerU作为一款功能强大的开源文档解析工具,为用户提供了从基础到高级的完整文档处理解决方案。通过本文档的详细介绍,用户应该能够掌握MinerU的核心功能、安装配置、使用方法和高级技巧。
随着AI技术的快速发展,文档数字化和结构化处理变得越来越重要。MinerU凭借其高精度、开源、可定制的特点,为学术界和工业界提供了理想的文档处理工具。项目的持续更新和社区支持也确保了其能够跟上技术发展的步伐。
对于初学者,建议从基础的命令行使用开始,逐步熟悉各种功能选项。对于有特定需求的用户,可以通过配置文件和API接口进行深度定制。对于企业用户,可以考虑使用Docker部署和分布式处理来满足大规模应用的需求。
无论您是研究人员、开发者还是企业用户,MinerU都能为您的文档处理需求提供有力支持。欢迎加入MinerU开源社区,共同推动文档AI技术的发展!